A key part of every developer's workflow is to search code. Code search today surfaces in the form of file-level/global lookup, or by ⌘/Ctrl clicking our way within an IDE. We search code to:
- Find code that can be extended or re-used for the feature we're building.
- Identifying the root cause for issues by narrowing down through code symbols found in the stack trace or error logs.
- Build a deep understanding of how things work by navigating, especially when new to the codebase.
- Find all occurences and replace them through an exact match, regex patterns or more powerful tools like ripgrep.
- Identify the impact of changes during code reviews.
And perhaps a few more.
 |  |
Diving deeper
If we take a step back and dissect these use-cases, the recurring theme is that search is a step in the process of solving a problem in a very specific context. But often, the specific context is a lot clearer than the exact search queries that need to be made.
Find code that can be extended or re-used for the feature we're building.
As a developer, I know the functionality of the code that I'm seeking to extend or write. But quite often (especially in large or unfamiliar codebases), I do not know the exact name or location of existing code that I need to look up. This leads towards a deep rabbit hole of guessing and searching through the codebase that is occasionally rewarding, but frustrating when it takes the whole day.
Identifying the root cause for issues by narrowing down through code symbols found in the stack trace or error logs.
Stack traces and logs are designed to help us find code while debugging. But not all issues have a stack trace or log that pin points the issue. When data looks inconsistent in a database or an unrelated code change caused an issue, I can describe the issue but there is no stack trace and requires deep reasoning with the codebase to find the root cause.
Build a deep understanding of how things work by navigating, especially when new to the codebase.
The problem with being dropped in a large codebase (which is anecdotally evident for me right now, as I now navigate my way around the VSCode codebase daily) is that it's hard to find the right place to start. And this problem repeats itself for every task unless I know every file in the codebase, which is unlikely in large projects and teams.
Find all occurences and replace them through an exact match, regex patterns or more powerful tools like ripgrep.
Today's system actually works pretty well for well-defined changes that can be structurally modelled as a search query. But if I were to say, "find every part of the codebase that renders a file list and add a small icon to the left", it's a lot harder and requires a developer finding every occurence and manually making the right kind of changes.
Identify the impact of changes during code reviews.
Impact analysis is a key part of code reviews that requires not just a single hop from a diff to answer how the rest of the system changes as a result. It's a traversal, across multiple paths and reasoning with each of them. And traversal is a lot harder to model as a search query in the way it's done today.
Hopefully by now, I have convinced you that the current state of search, while powerful, doesn't do enough for me as a developer. So, as developers, how can we make this better? This is one of the main questions we've been plugging through at CodeStory this week.
We started by trying to break down the problem into a few facets.
Solution space
I know the exact code symbols I'm looking for
Great! Lexical search (as it exists in IDEs today) is the answer. In conjunction with the modifiers offered by the IDE, like match case, match word, regex pattern and filters like glob patterns to include and glob patterns to exclude, this gets you straight to the code symbol. Pairing this with tools for replacing code using the matching patterns, this solves the simplest use-cases that we have.
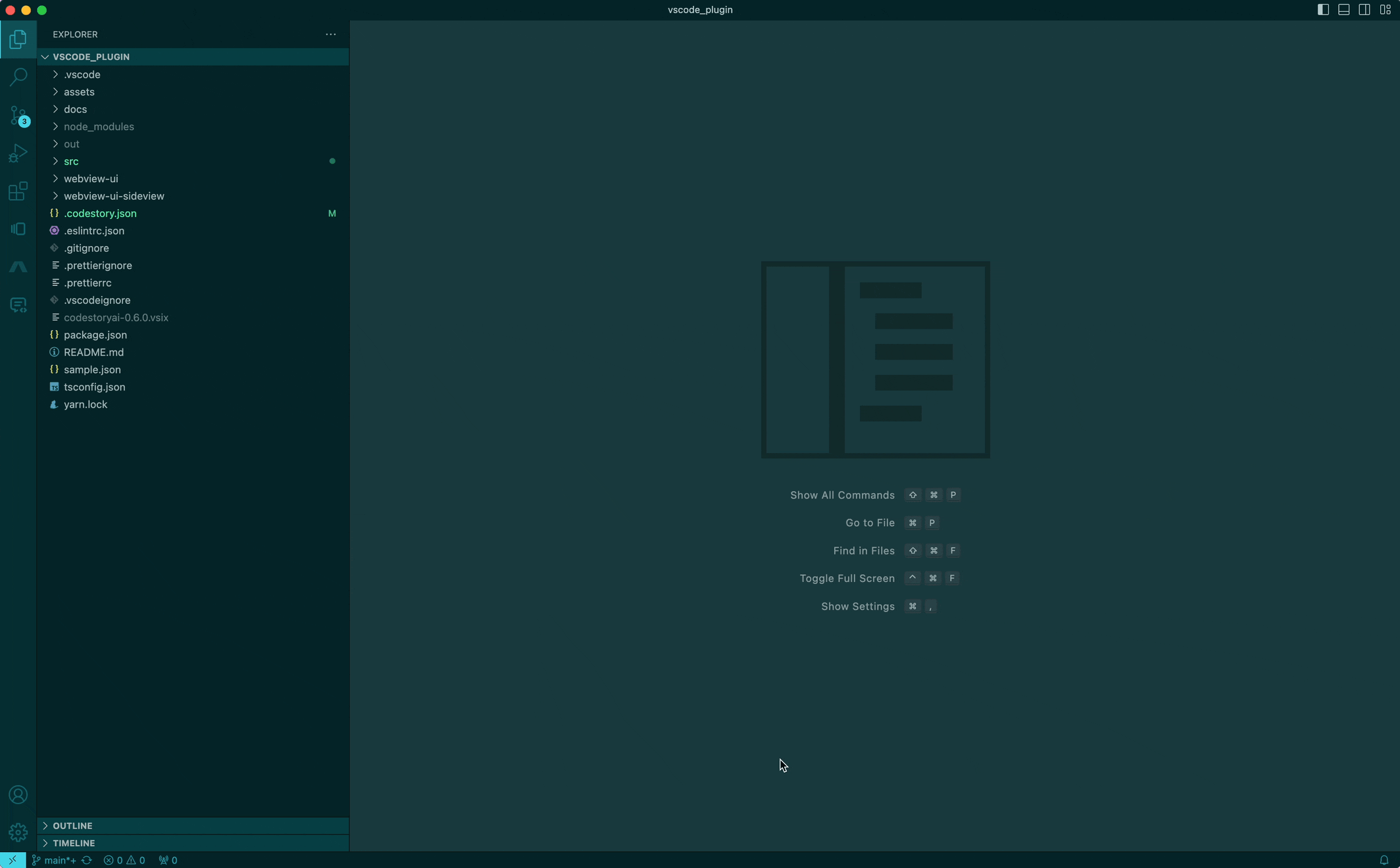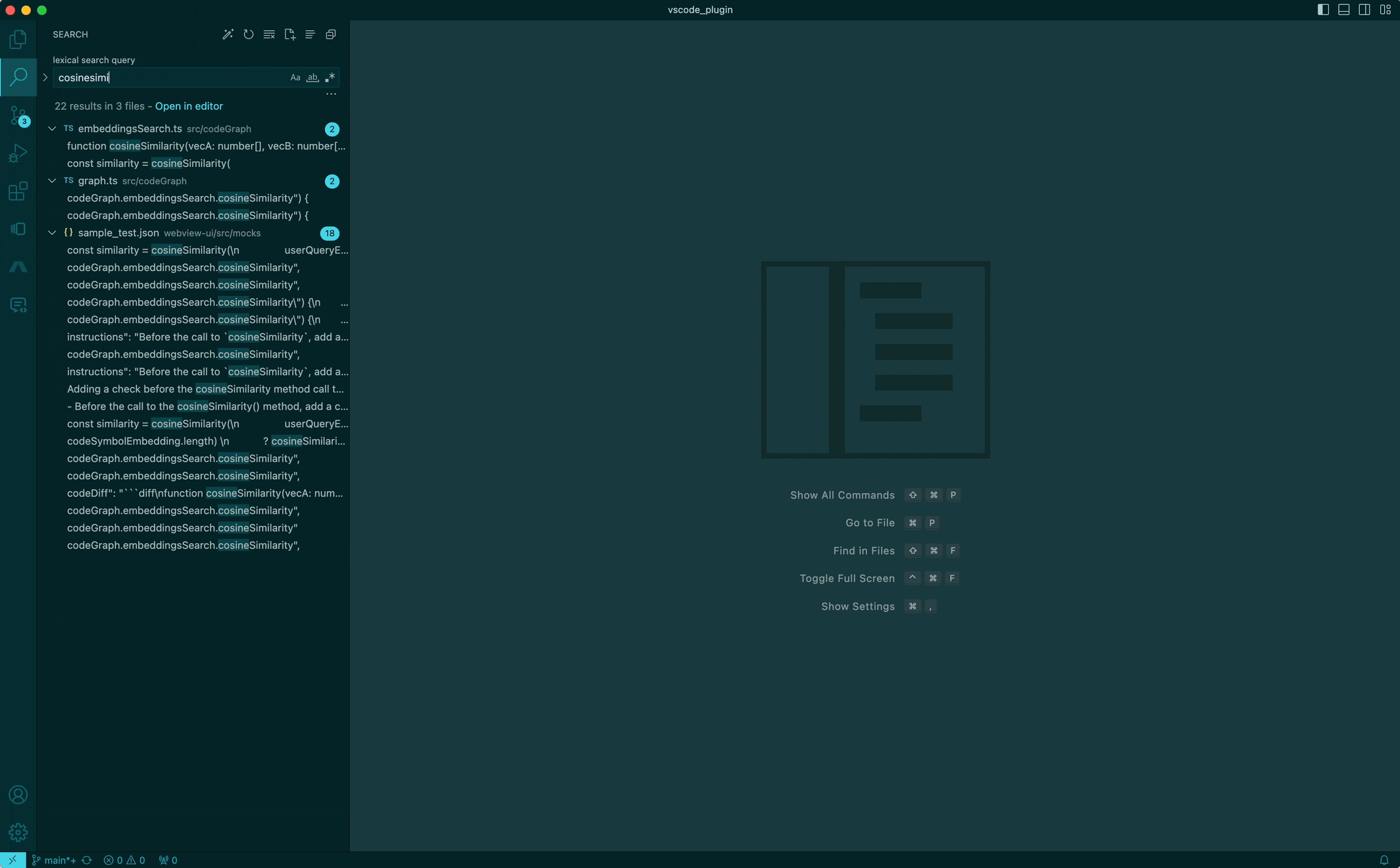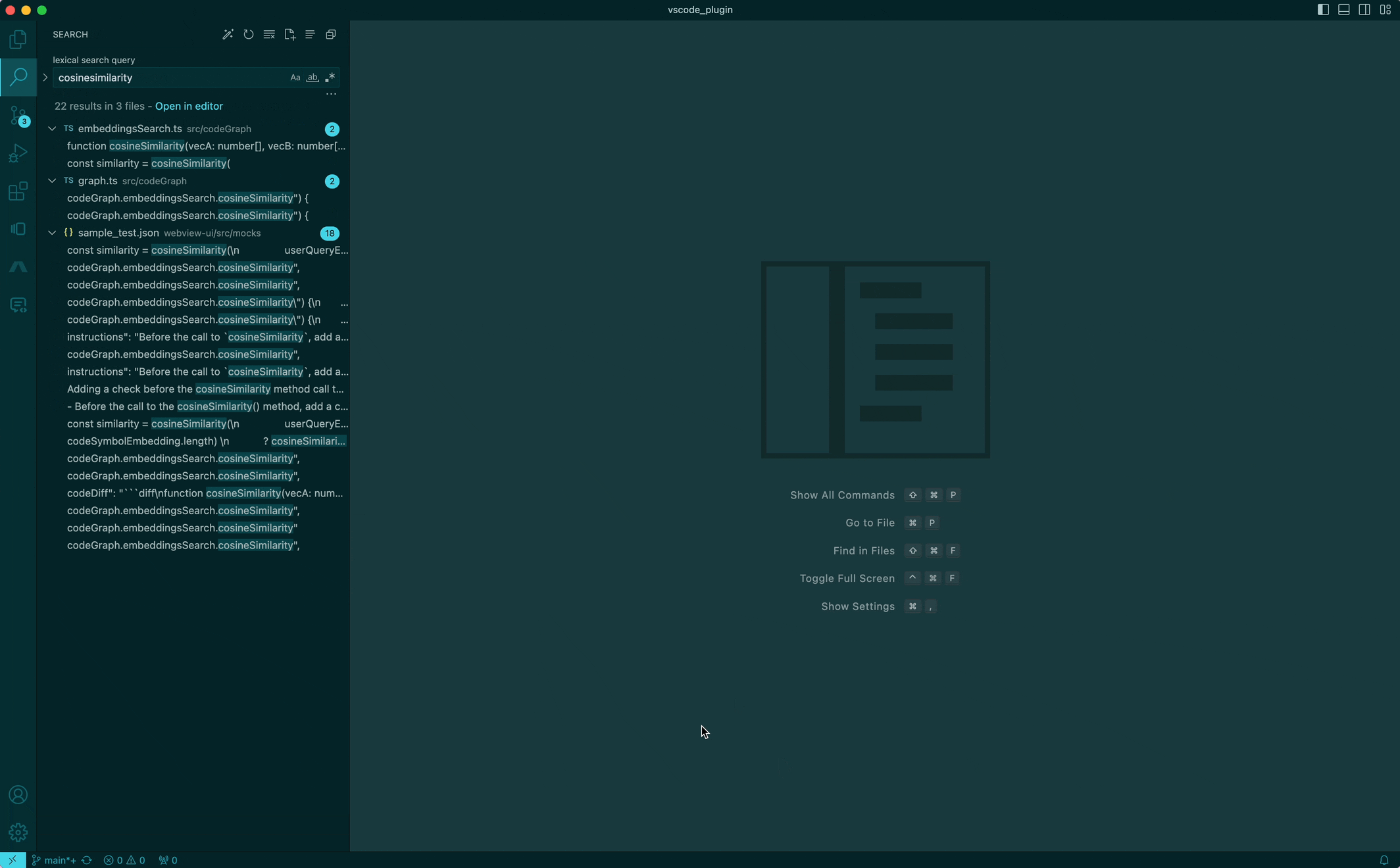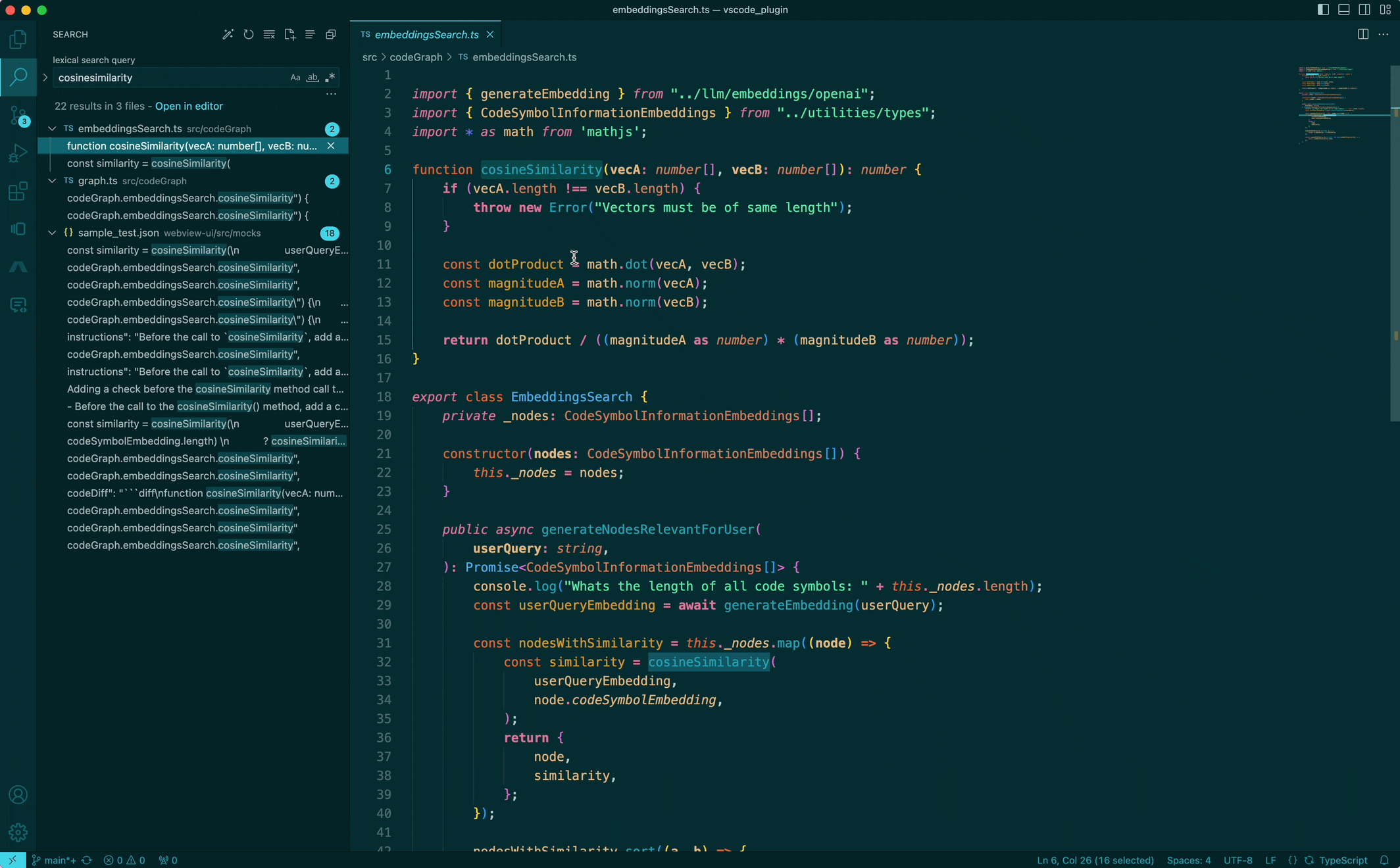
I'm looking for something specific, but don't know where
The way I'd imagine looking for something specific would just be to ask for "cosine similarity" to find the cosine similarity implementation, or "async payment processor" to find the worker implementation that processes payments. We're pretty used to this type of search (aka Semantic search) from Google for so many years — but why can't we have this for searching code? So... we built it!
While this sounds trivial (“just pass every file through an LLM and query, yea?”), we can improve it in big ways with some small observations. Code, unlike natural language text like books or articles, is modular (in the form of being divided into packages, files and functions, for example) and has a lot of structure (in the form of being connected through imports, function calls, etc). Without leveraging this structure, a file in isolation might not know how the dependencies/dependents are written or can have unrelated functions that are all being used elsewhere. This addititional context can be quite critical to tokenizing correctly and generating better embeddings.
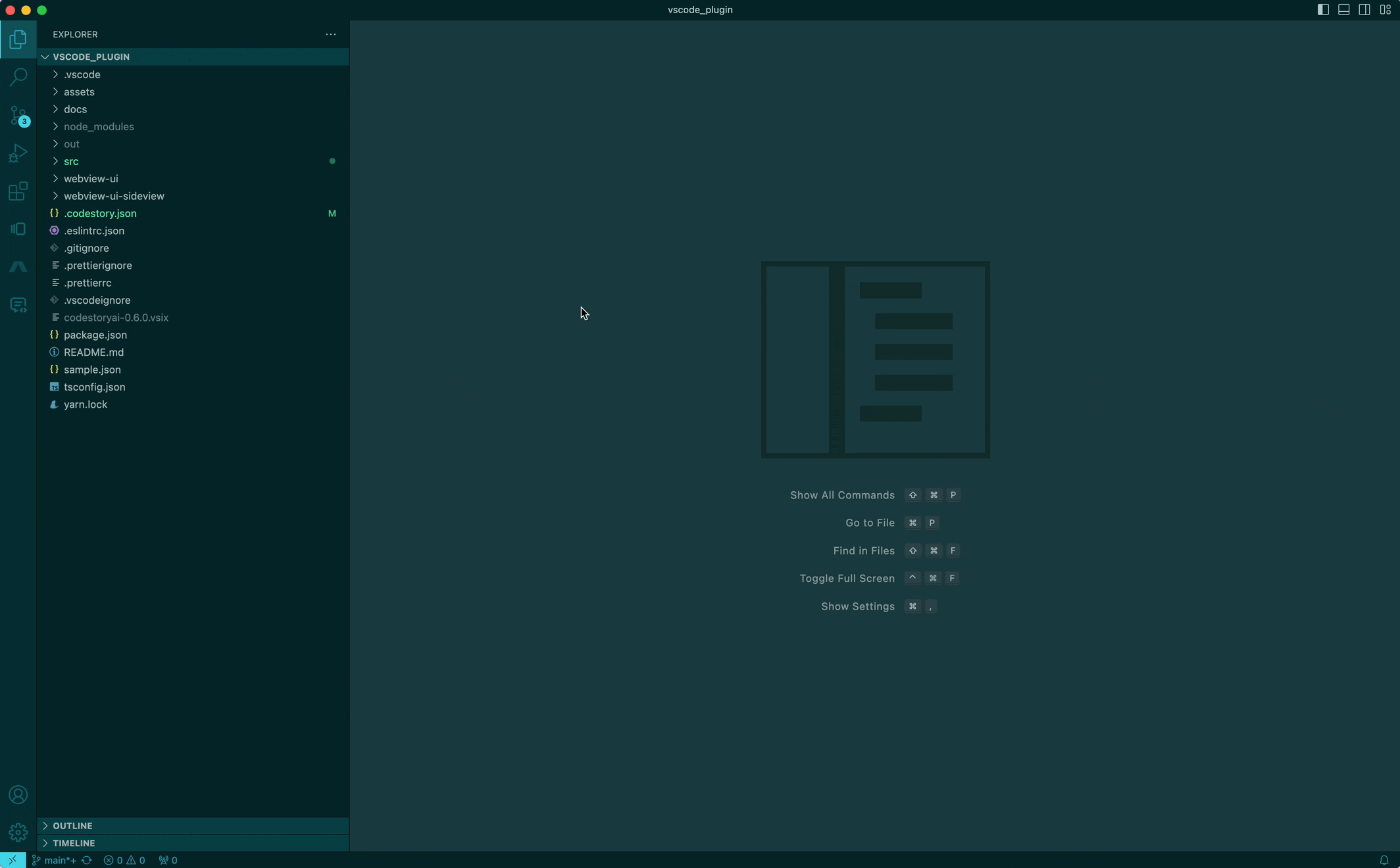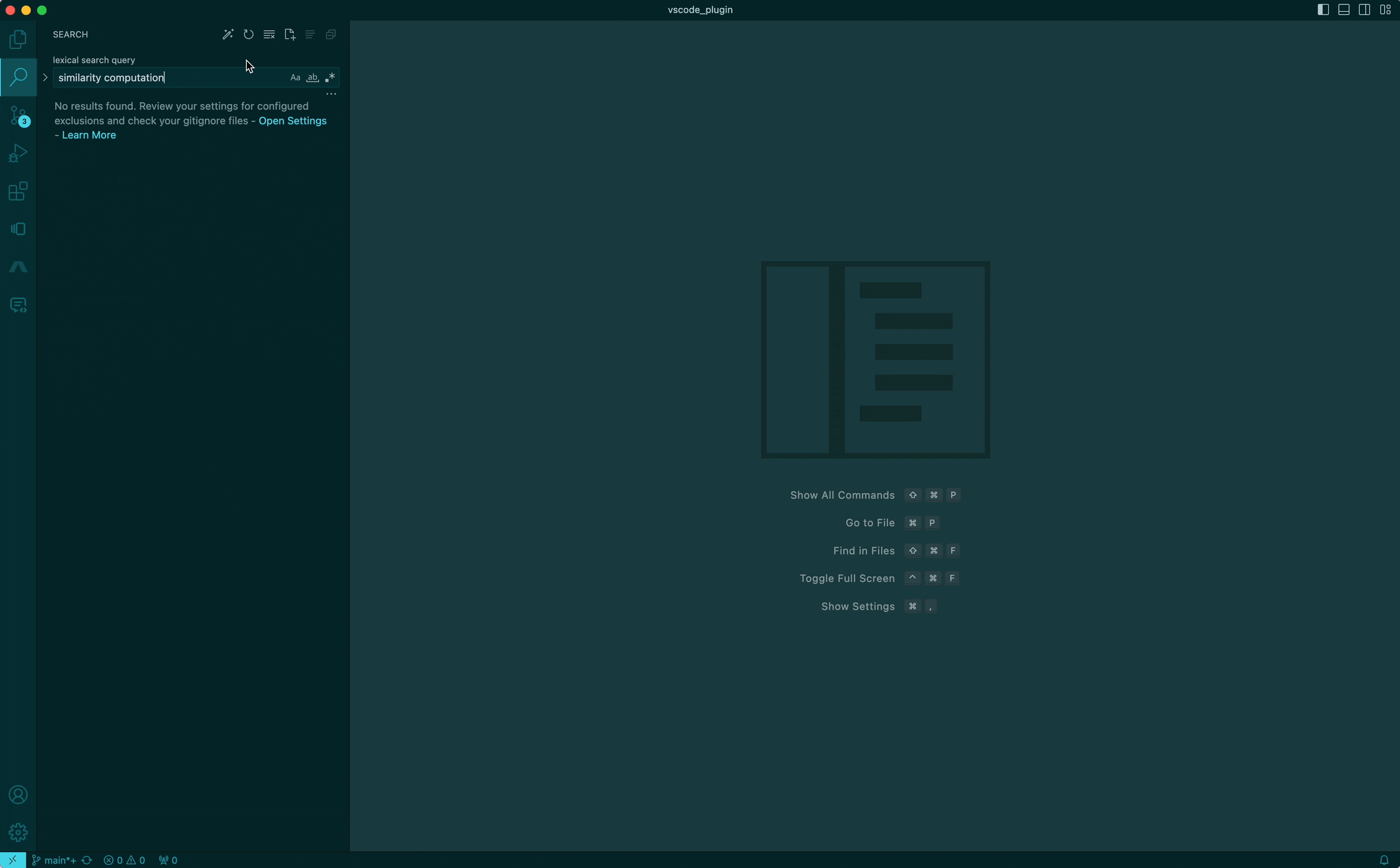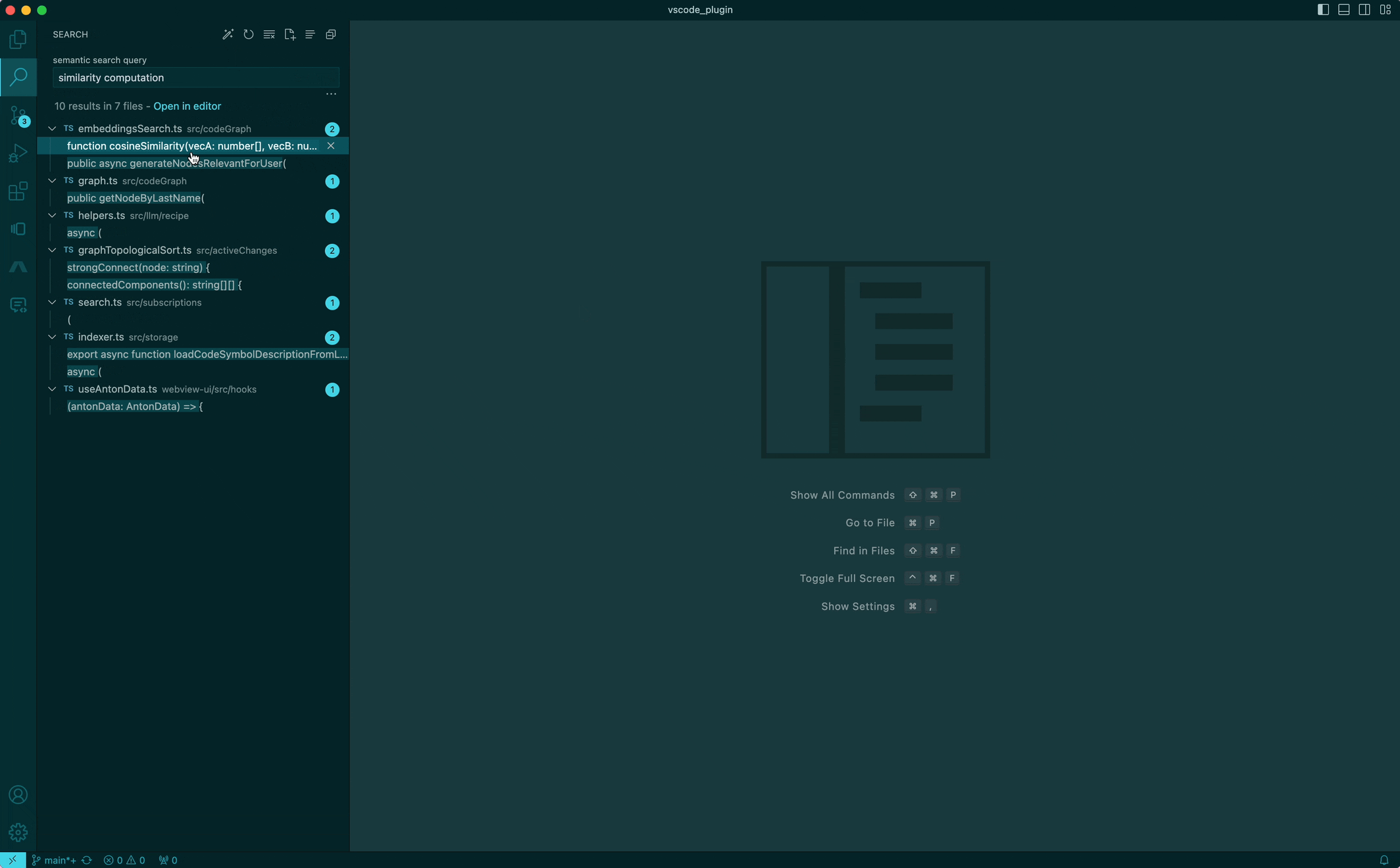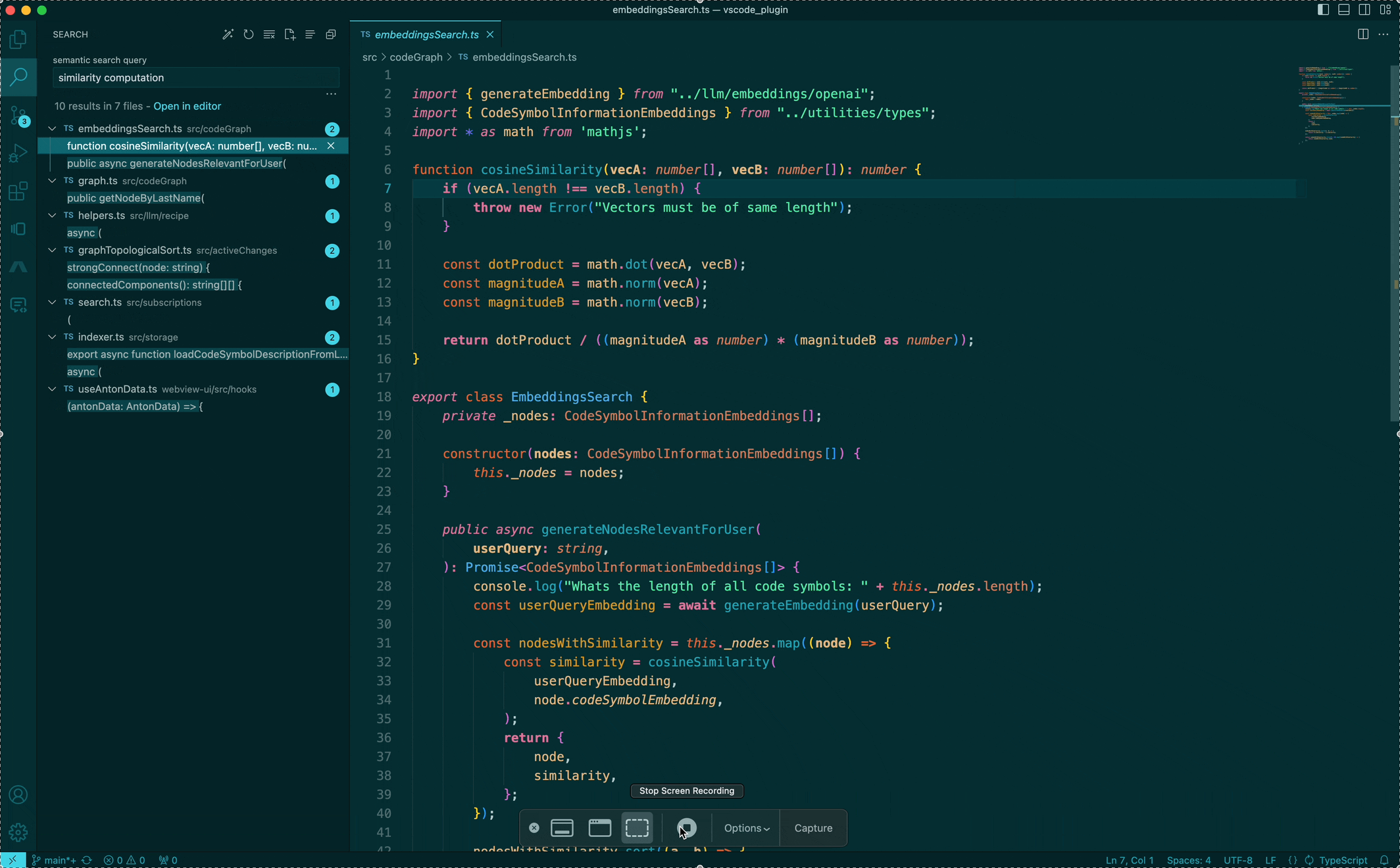
Pairing this experience with the IDE's search UI, we can now search for code as concepts, and get back a list of results that are sorted by relevance. This is a big step forward in leveraging semantic search for code and we're excited about improving this further!
I want to explore broadly and don't have a place to start
I'm going to use our experience of building the previous feature to explain this one. In order to augment VSCode's built-in search implementation, we needed to find answers to so many questions: Where does the UI implementation start? How are the classes composed and what are their responsibilities? Is it all in one module? Where is the search logic and how does the hand-off happen from the UI? How are results populated and kept updated?
Clearly, this is not a simple, static search query that a list of file paths can answer. And honestly, what you do if you were in this situation? Ask a senior engineer who knows this well to give you some pointers, right? Well — we didn't have one. So, we built one!
This is where our AI agent comes in. An ideal AI agent should be able to guide you through the codebase, answer questions about the codebase and help you find the right place to start. Well, we want our AI agent to be able to complete end-to-end tasks, but let's start here for now. In order to perform these actions, we need to provide the agent with a few things:
- An index of the codebase that can be queried. Oh, hey, we just built that earlier! Sweet, we just need to give the agent access to the index.
- The ability to breakdown a query into smaller chunks and extract this information from the index.
- Most importantly, use these smaller parts to go deeper into the codebase. Today, we structurally navigate code by clicking around in the IDE (powered by the LSP) or just how a particular file is structured (syntax trees). Integrating these tools with the agent allows autonomous navigation of the code to understand how different pieces are linked together. "How the code flows", really.
- Finally, present it back to the developer as a cohesive story rather than just a list of files.
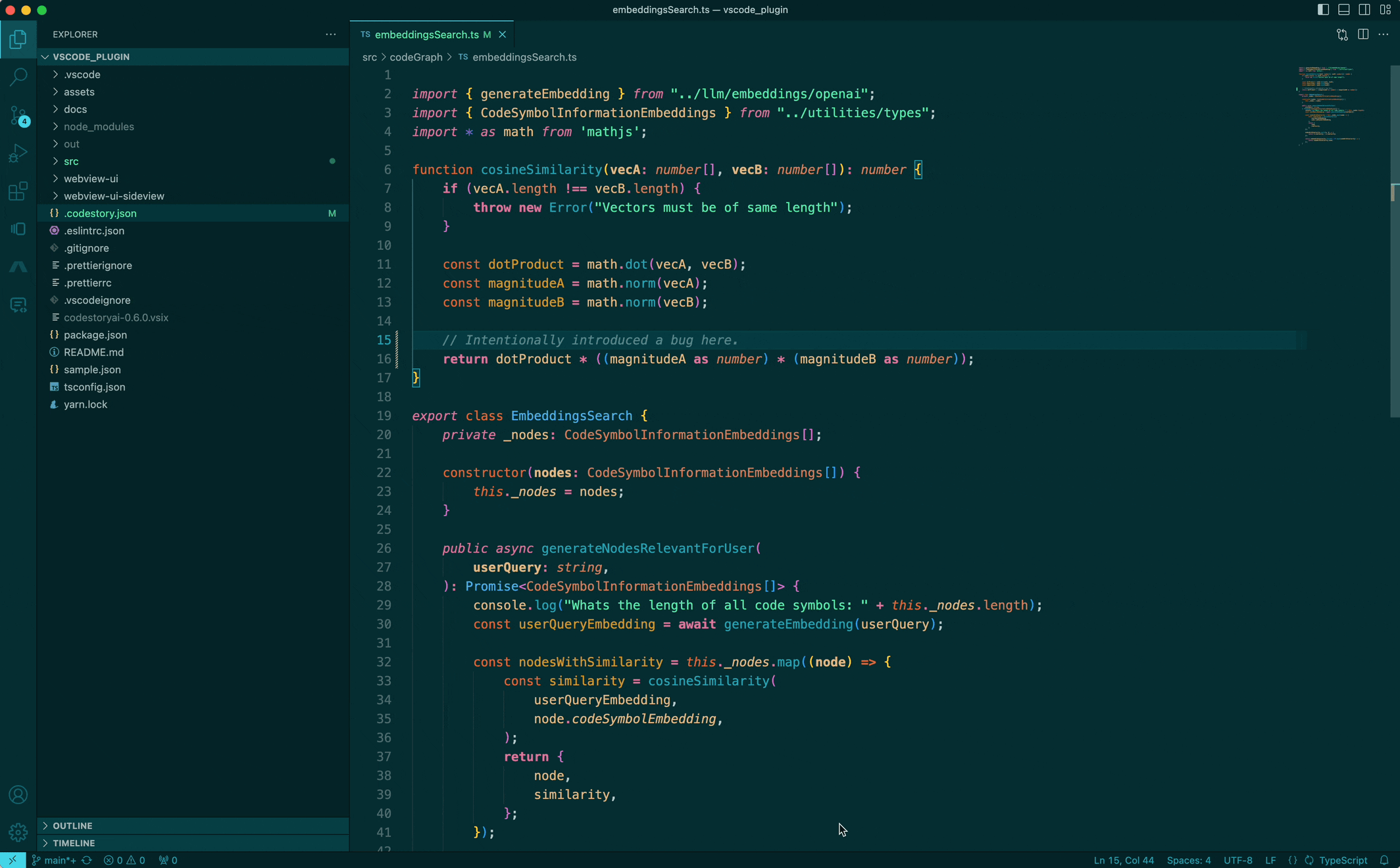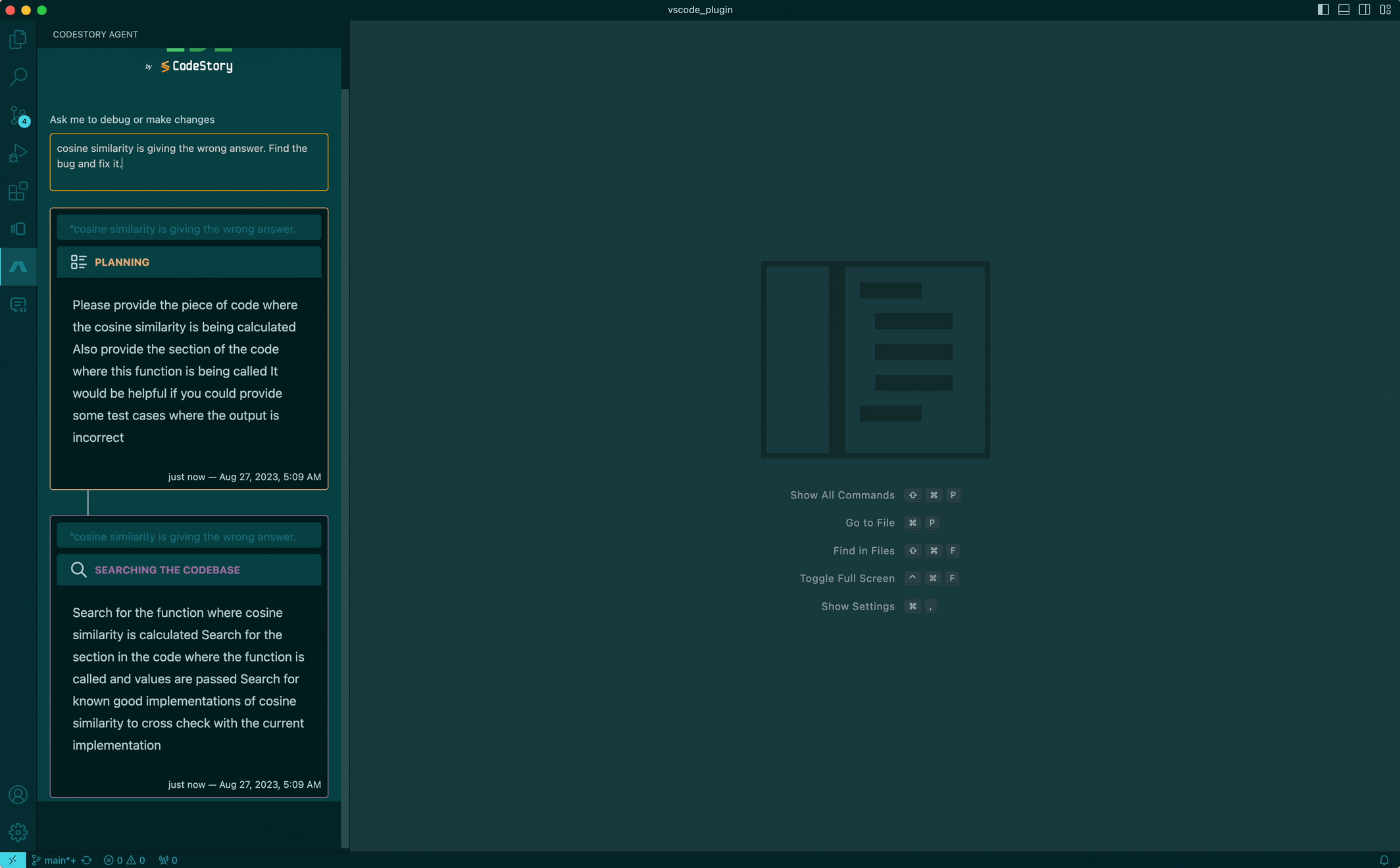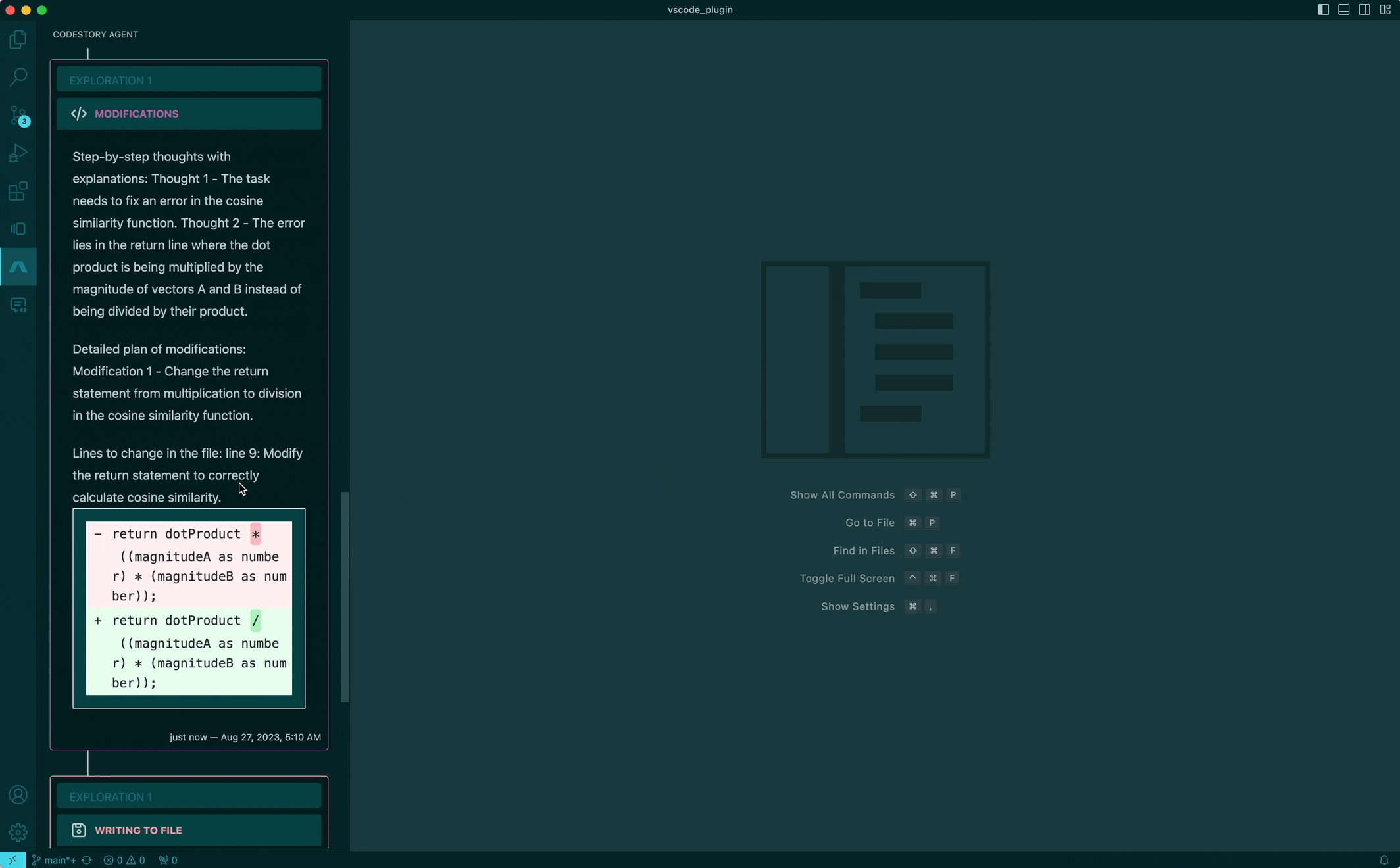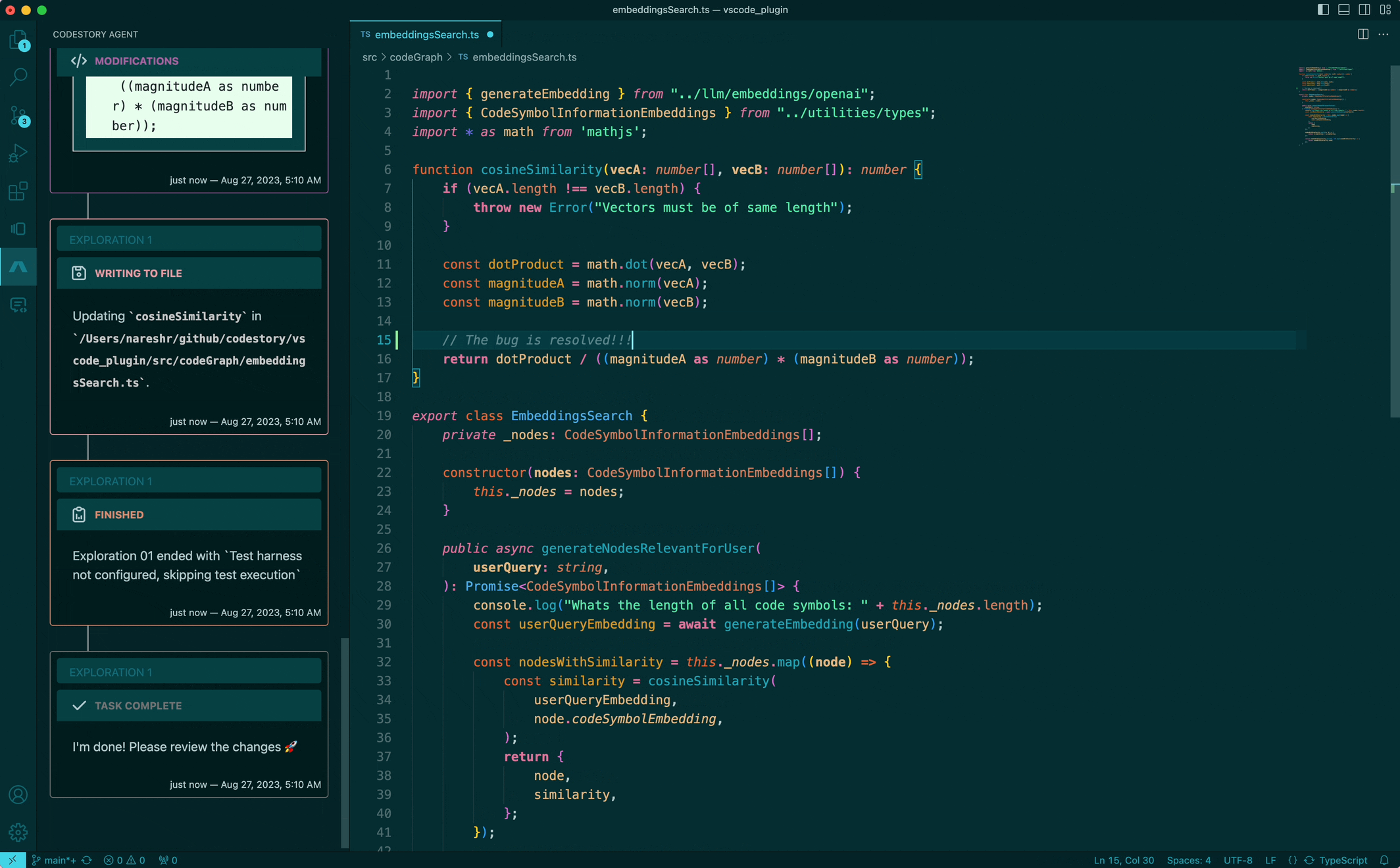
That's exciting, isn't it? This is something we have already made a lot of headway into. While the UX is still a very major WIP, the sneak peak of our agent above shows it being given a task, which it automatically breaks down, makes a few searches and navigates the codebase before getting to work. We hope to be able to offer this experience to developers soon! A very exciting aspect of this is that the same foundational building blocks we build to aid developers is also used within the IDE by the AI agent. The AI agent really becomes another developer to work with, not just a pair programmer.
Try us out!
Aide by CodeStory is an IDE that's still only 3-weeks old but powers a lot of powerful features. We're still in the early stages of building this and would love to hear your feedback. If you're interested in trying this out, please try out the beta at codestory.ai and get started!
Until next time, happy coding!