TLDR: We use a mix of tree sitter queries and parsing the LLM output as it streams to generate editor edits to do in-place edits on the editor.
VSCode allows you to create an in-line chat interface (insert link) which can edit code which the user has selected, this allows you to fix errors, generate documentation and follow user prompts to make edits.
 |  | 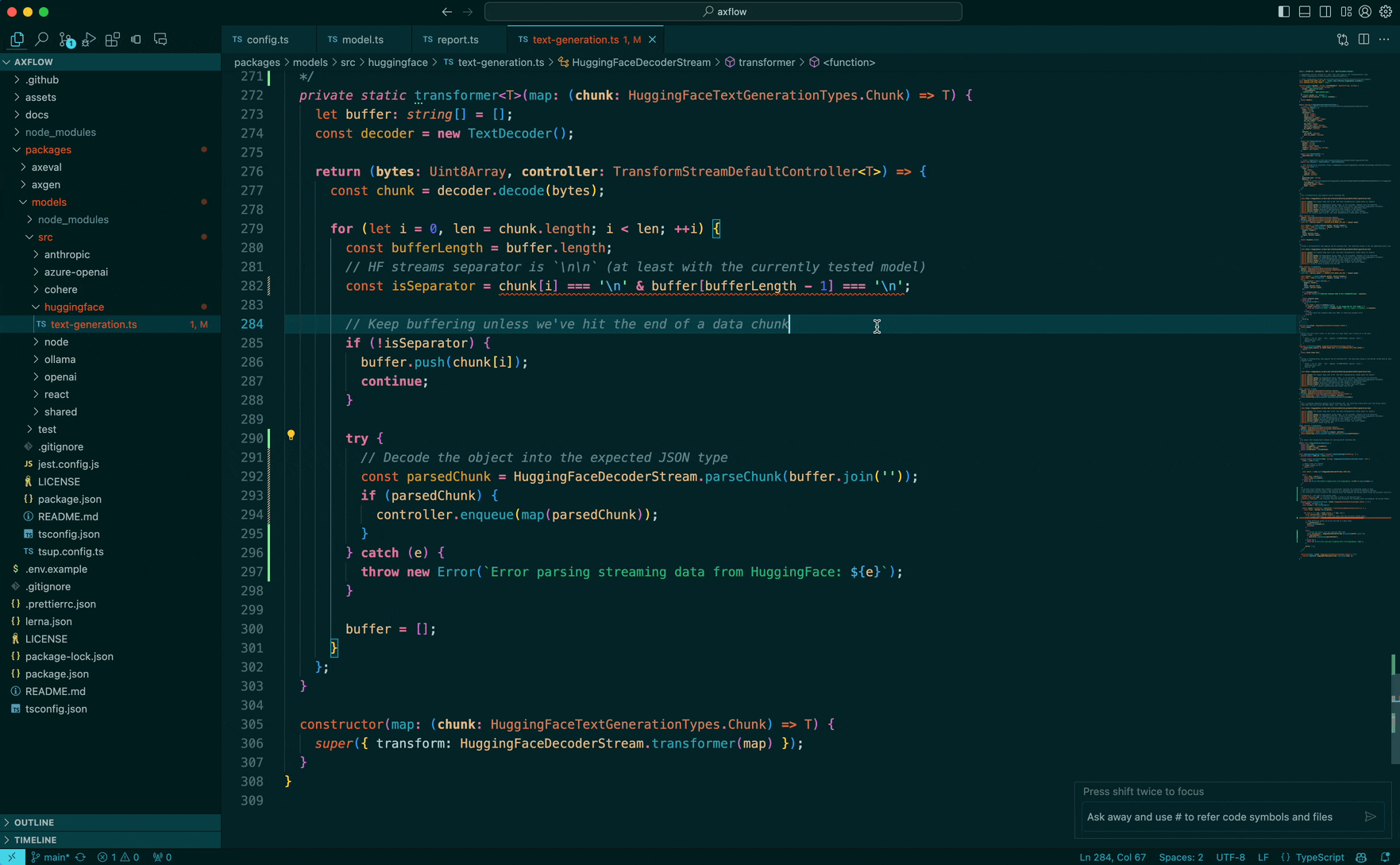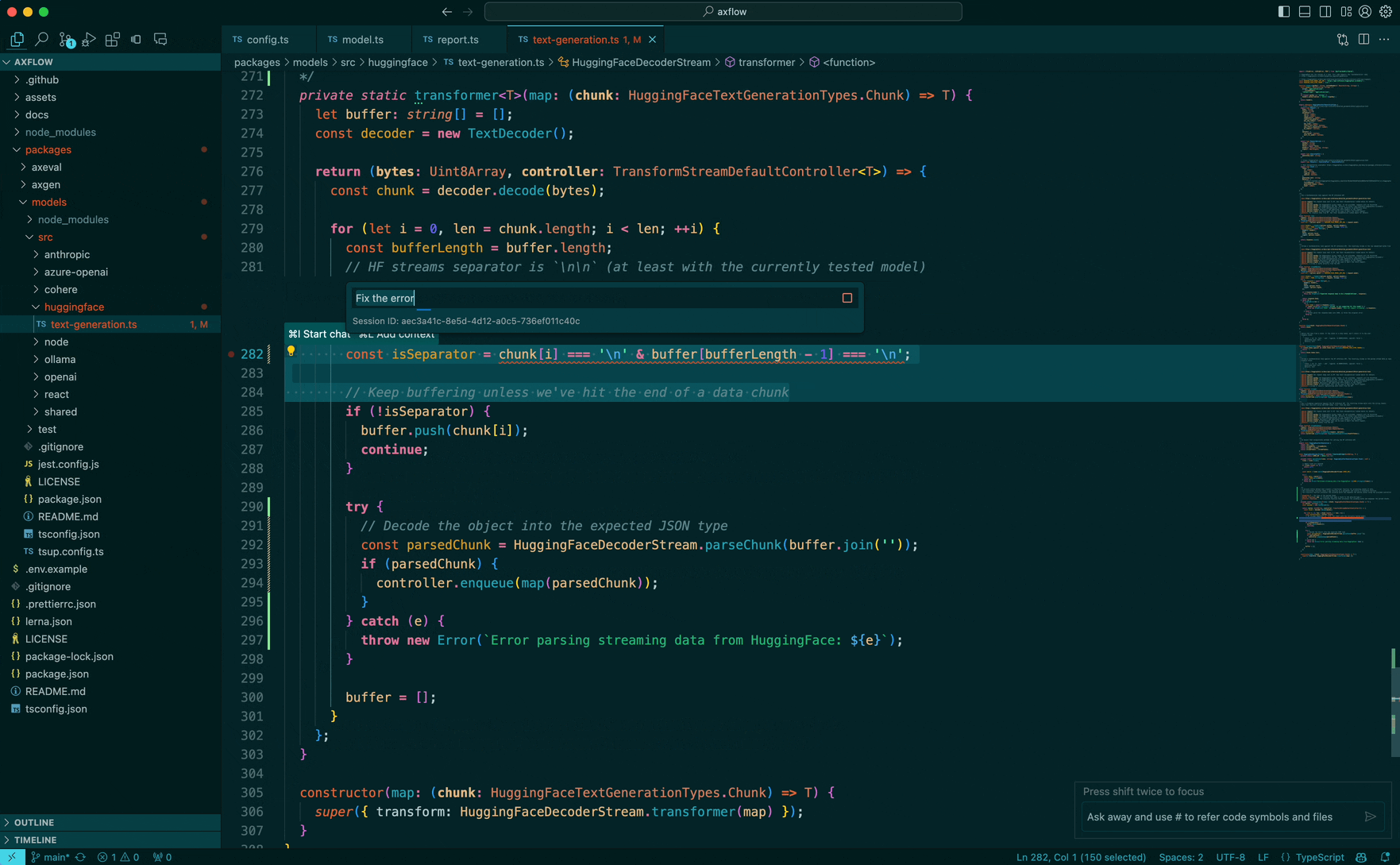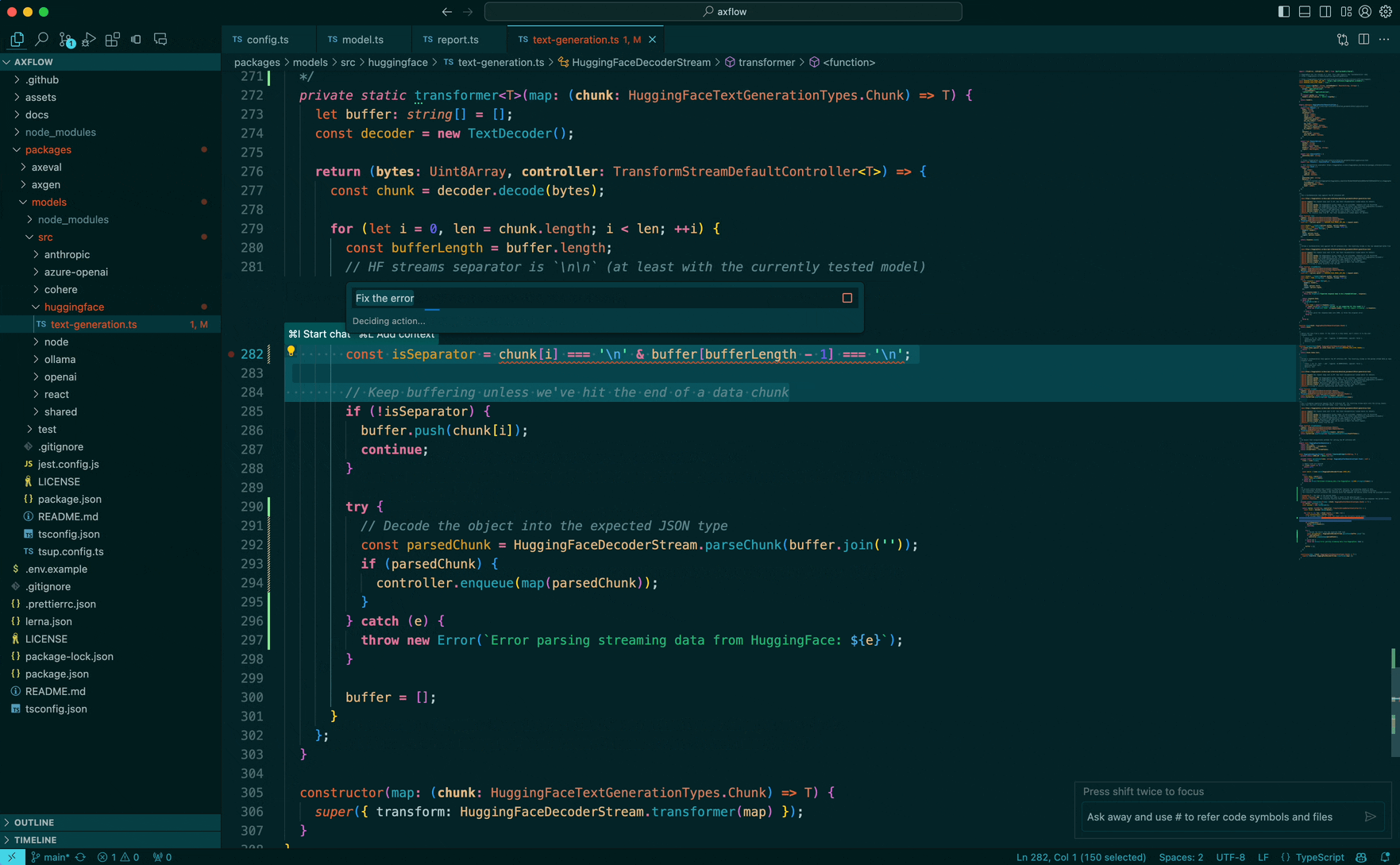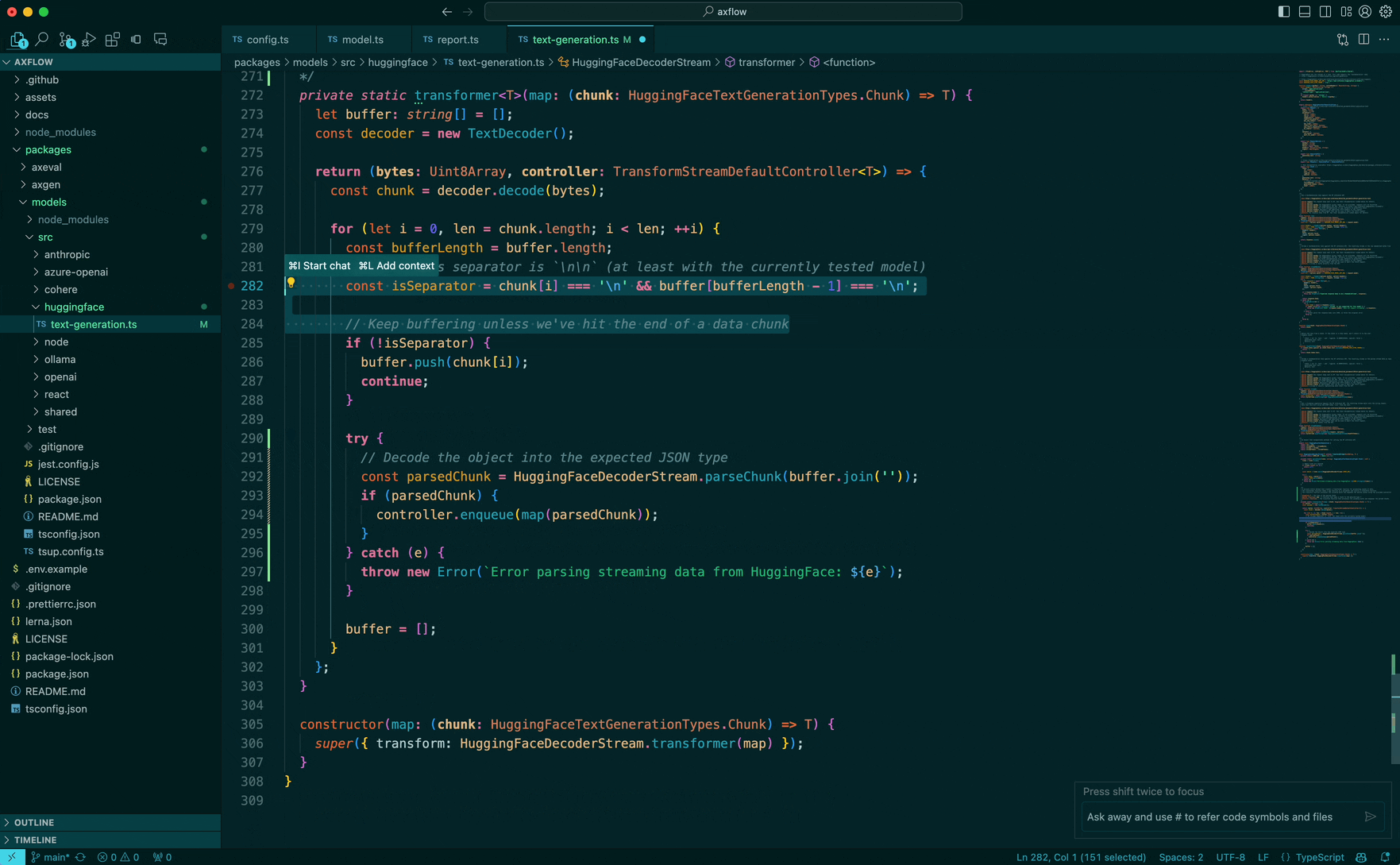 |
At CodeStory we wanted to bring this experience to all our users! and we took quite a few steps to make sure that the code generation just works.
We want to illustrate a simple workflow and break it down from the moment the code is selected to the code generation happens in the editor. At each step, we will illustrate how to prompt the model and parse it so the editor can show the edits to the user.
The prompt we are going to ask the model is: “Can you wrap this in a try/catch” and we are working in a typescript codebase. Let’s dive in:
User code selection and range detection
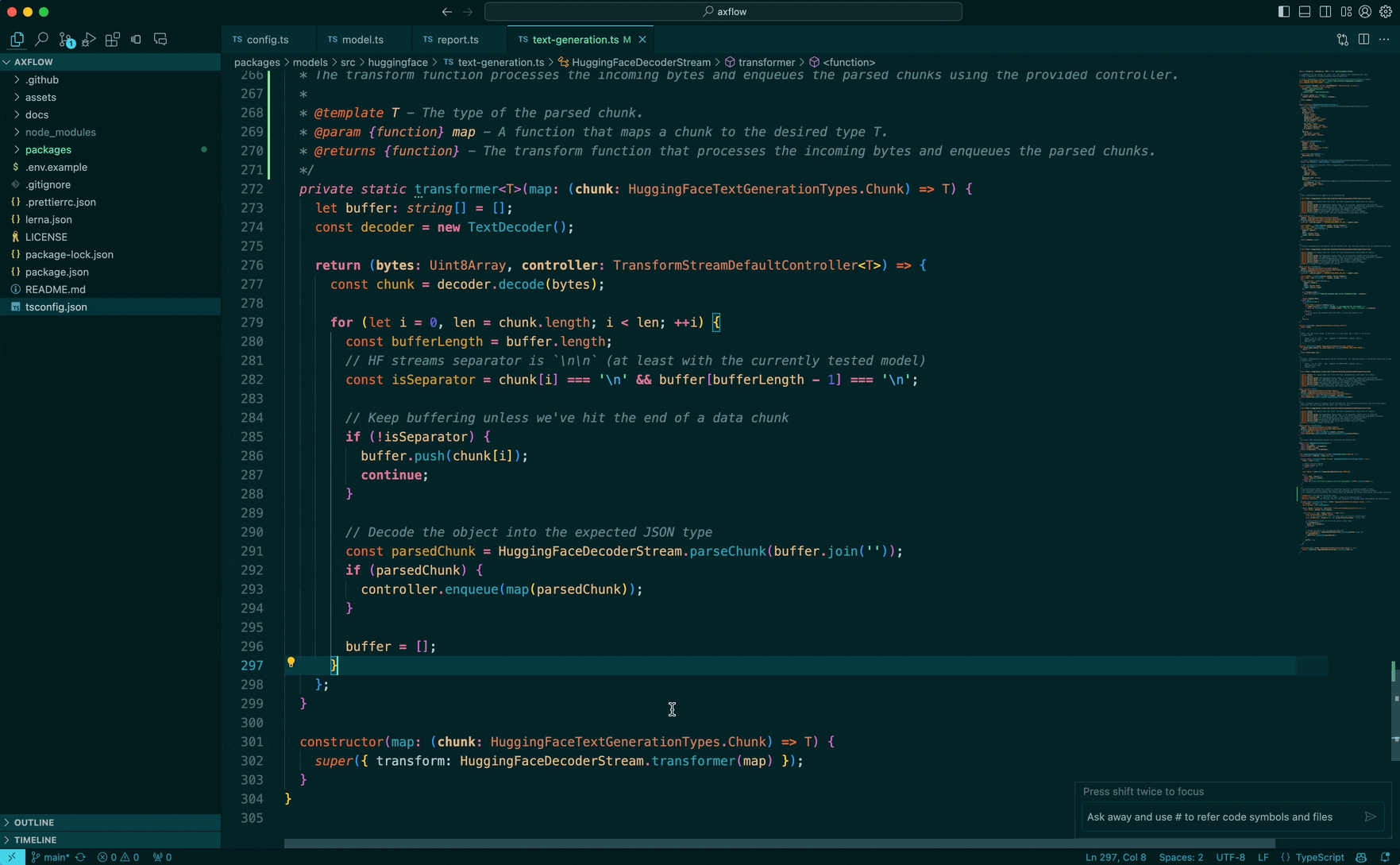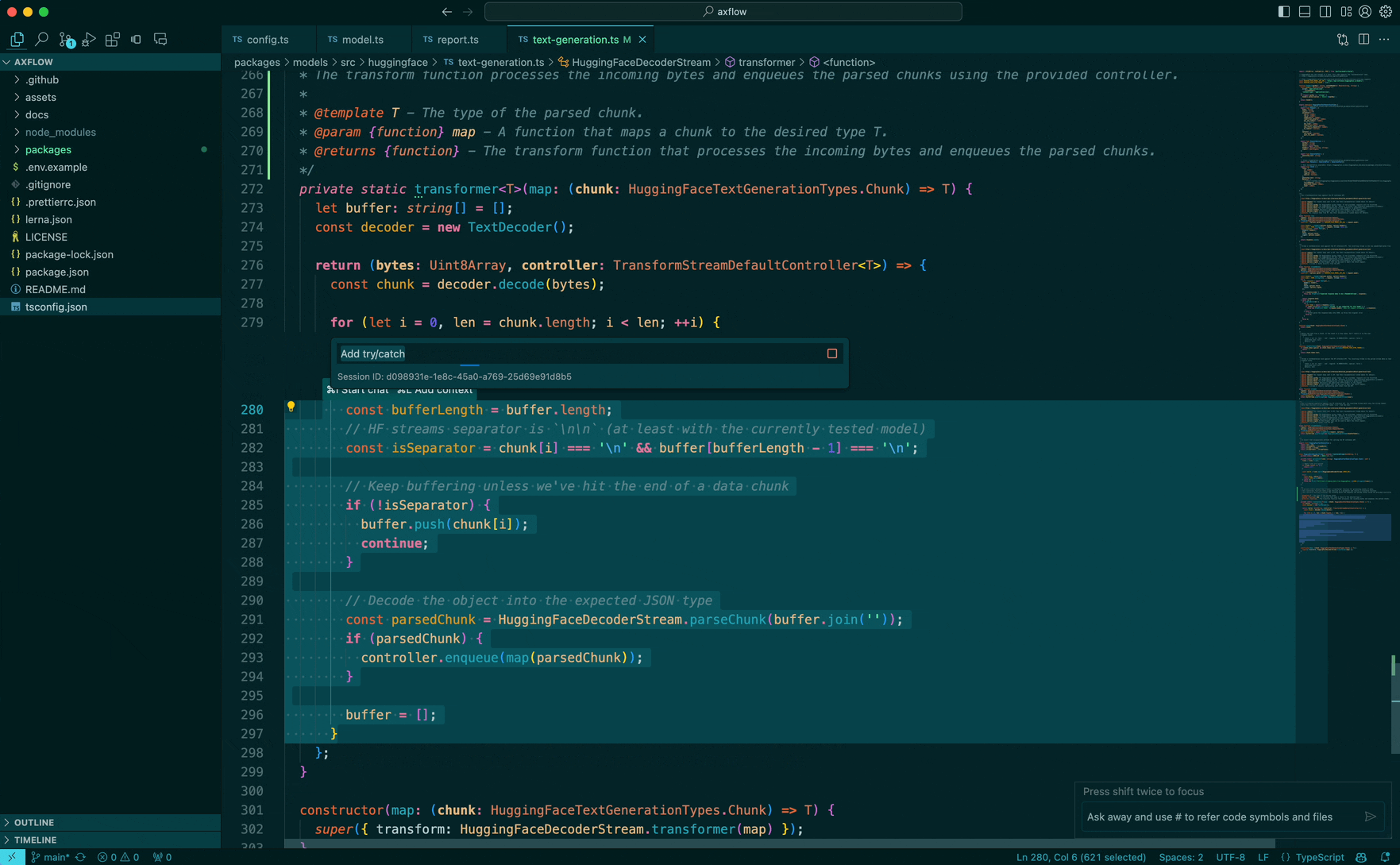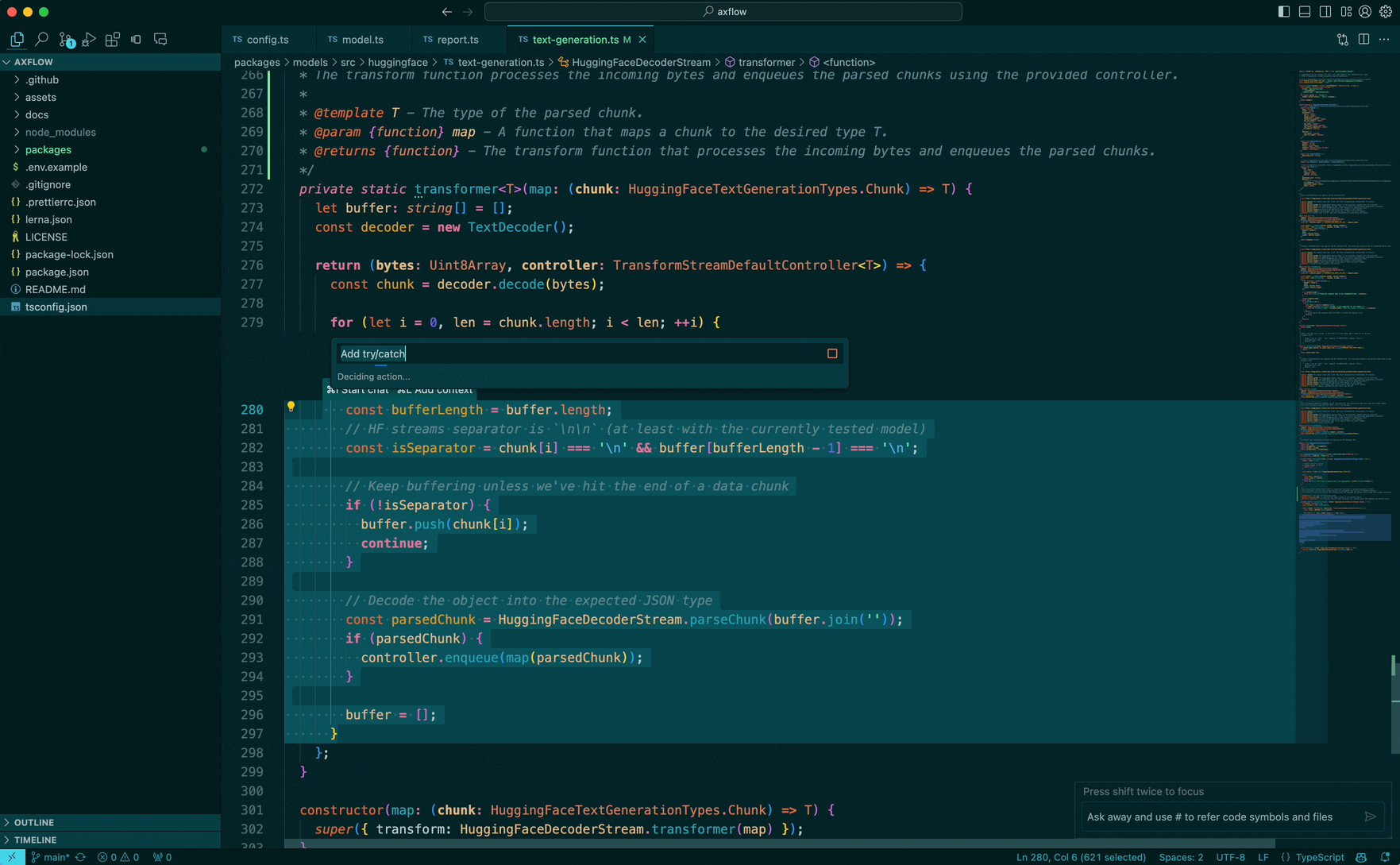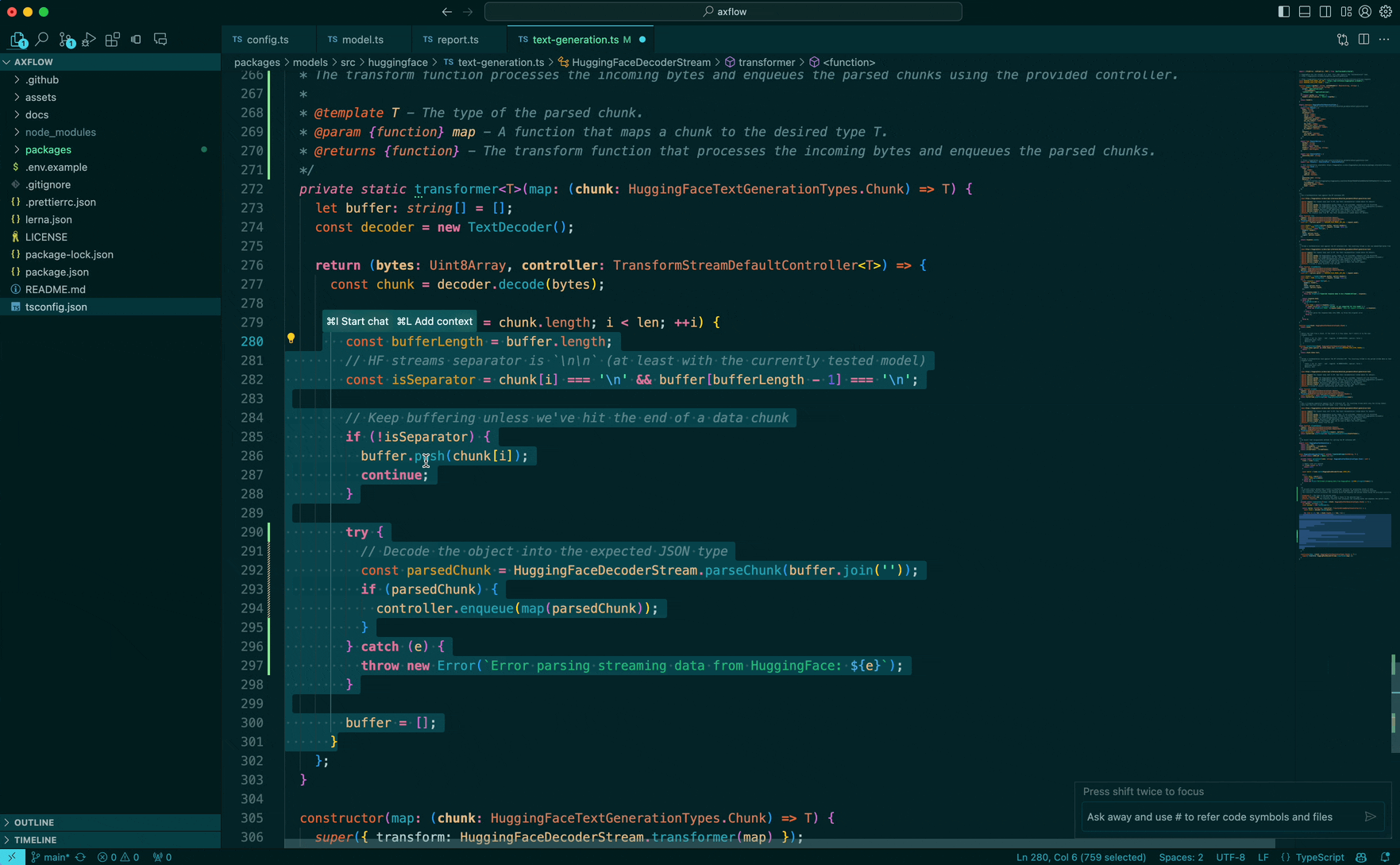
Say the user is working looking at a code snippet which looks like this with the selection highlighted:

Now the user query “Can you wrap this in a try/catch” requires changes which need to be made across the body of the function which is not captured in the selection the user has done. Here is where tree sitter helps us out.
We can use a tree-sitter query which can highlight the functions, classes, and other important code symbols which are present in the code, along with the identifier for the code symbol and the body of the function. For typescript we use the tree sitter query below:
Which gives us a lot of information about the code symbols and its various attributes, if you run it on the playground , you can see how different parts of the code get coloured and recognised:

Now that we get the function body (which is the body content of the function), the identifier (which is the identifier for the function or it’s name) and the whole function node, we can try to understand which function the user talked about in the selection pretty easily.
In this case the user selection was from the line: 264-273 in the original code of the screenshot, and for the function we are interested in the body_node is from the line: 264-288 and the function_node is from 263-289
Here we do the next step in our algorithm which is called expand-range.
Since we ourselves are lazy enough to not select the whole function, the original selection done by the user might not be complete and is partial, so we expand the selection. Visually you can think of the expansion step as the following:
becomes:
The algorithm for this is pretty simple, we find the function nodes which totally cover our <selection_start> and <selection_end> anchors and get those function nodes out.
But since often times the user is interested in a single function and not multiple at the same time, we run a heuristic which allows us to pick the most important function if multiple get selected.
The heuristic in question looks at how much of the function we were originally covering from our selection and ranking them accordingly, in our toy example since function a is covered a lot more, we use that as our main function to change.
Great! now we have a function selected and have properly expanded the user selection, how do we prompt the LLM?
Taking the selected code and generating prompts
Anyone who has worked with LLMs knows that context matter, and in code generation there are multiple ways to generate code, there is fill-in-the-middle, plain old code generation from prompts. In practice what we found was that fill-in-the-middle kind of prompts work really well (the LLM in question here are GPT3.5 and GPT4)
Another observation which we use here is that the LLM is going to edit a whole function, often times the prefix is a bit more important than the suffix of the code (this is a personal observation which is based on how most code is written: top-down in a file)
Since the context window is also limited, we have to be careful about the data we provide. LLM’s also have the Lost-in-the-middle behaviour where they don’t pay much attention to what’s in the middle of the context, but rather on what’s towards the top and bottom of the prompt.
The problem boils down to the following:
- send LLM the code we want it to change (duh!)
- send some context about the code above (which is often times important)
- send context about the code after the selection (which is not as important)
- keep in mind the Lost-in-the-middle behaviour of LLMs
- also give the LLM some space to think about how to change the code
Lots of things right? But we can do something smart here using the system prompts and special markers which bias the LLM to not hallucinate and produce output which we can parse as quickly as possible.
While doing code generation another interesting fact which we found by experimenting and looking at how the LLM itself generates code gave us a few ideas.
When asked to generate code the GPT family of models output code which looks like this:
language here can be any of typescript, rust, javascript etc…
the backticks are super important markers for parsing cause they give us a hint on when to start.
So our system prompt along with the messages ends up looking like this:
The LLM pays special attention to the system message and we tell it to always spit out a single code block so we can start parsing quickly!
Now for our next step, we have to generate the chat prompts to send to the LLM, as described before we want to send more context from the prefix and less from the suffix.
One easy and cheap trick we use is to expand the selection range upwards and downwards at the same time, but add 3 lines from the prefix for each line added in the suffix, keeping the ratio 3:1 . This is a hand waved ratio which works pretty well in practice!
Bringing this all together our prompts end up looking like:
We use temperature setting to 0.1 (since we want the LLM to be imaginative but not too much?), we found this to work well for solving problems and code editing but not change too many things in the code.
Often times the completion of such prompt looks like this:
Great! so we got the LLM to output code, but we are not done yet, the magic of how LLMs work is that they stream their answer, can we start working quickly and decipher how the code has changed and what edits we have to make?
Process the stream as soon as you can
If you set stream=True on most LLM models, you can get the delta of what has been produced. This is often handy for many reasons:
- using
stream=Truein practice leads to a more stable connection with any LLM you are working on (the network stays fresh and there are fewer instances of timeouts or errors creeping in) - you get incremental updates which is a great UX win, cause no one wants to wait for 5-6+ seconds before seeing an output.
So how do we start processing this stream of output from the LLM, in our case because of how the output from LLM looks like, we can use a few tricks (read as regexes and make assumptions about the code generated to fix things!)
We created this very simple class in our editor which takes the output of the stream and then spits out the lines (which are separated on \n): functionally you can think of the class as:
spit_out_lines(delta: string)->(Stream<Vec<string>>) we basically accumulate the delta until we hit a newline character and generate a stream of lines to work with.
And if you remember our code output is always in a block of ```!
This allows us to detect when a code block starts and get the code as quickly as it is streaming.
But and this is a BIG BUT, we are not done yet! If you are using a code editor right now, have a look at the indent style of your code,
This is a touchy topic of spaces vs tabs
The code generated by the LLM does not follow any such convention, so we have to fix it!
Once we fix it and its often easy enough to fix (you can look at the line you were going to replace and find what kind of indentation it’s using and see the LLM’s output indentation style which is often times spaces and change it)
But once we fix that, with our spit_out_lines function we can confidently tell the editor that we want to replace the lines!
And finally, we can go from code selection to code generation, inline in the editor!