Reasoning models like o1, r1 and the new google-gemini-2.0-thinking models are entering a new paradigm of models which do a lot of thinking. They do this via a new realm of resource utilisation called compute time scaling
These models are autoregressive in nature as before but are trained to think for a long…way long. This enables these models to do extensive “thinking” and in turn when they generate the answer it is often of very high quality.
The thinking these models do is more free-form and unrestricted. OpenAI went all the way to hide the thinking since it might violate their AI guidelines and honestly I am not surprised. If you pick an average human and ask them to think about the problem, the mental gymnastics they perform to solve a problem might not even make sense on paper or even be something which we end users can understand.

Pre-training
The above diagram from Ilya's recent talk at Neurips shows that the paradigm which is growing well and fast is compute, data is restricted (to an extent) but compute is the one part of the equation which will continue scaling.
The figure below demonstrates that different biological systems scale intelligence differently. The chart from Ilya’s talk is especially enlightening since we often think of Transformers as the final architecture to scaling intelligence but nature points that between Hominids and Non-human primates there is a clear difference between the intelligence with brain mass density.
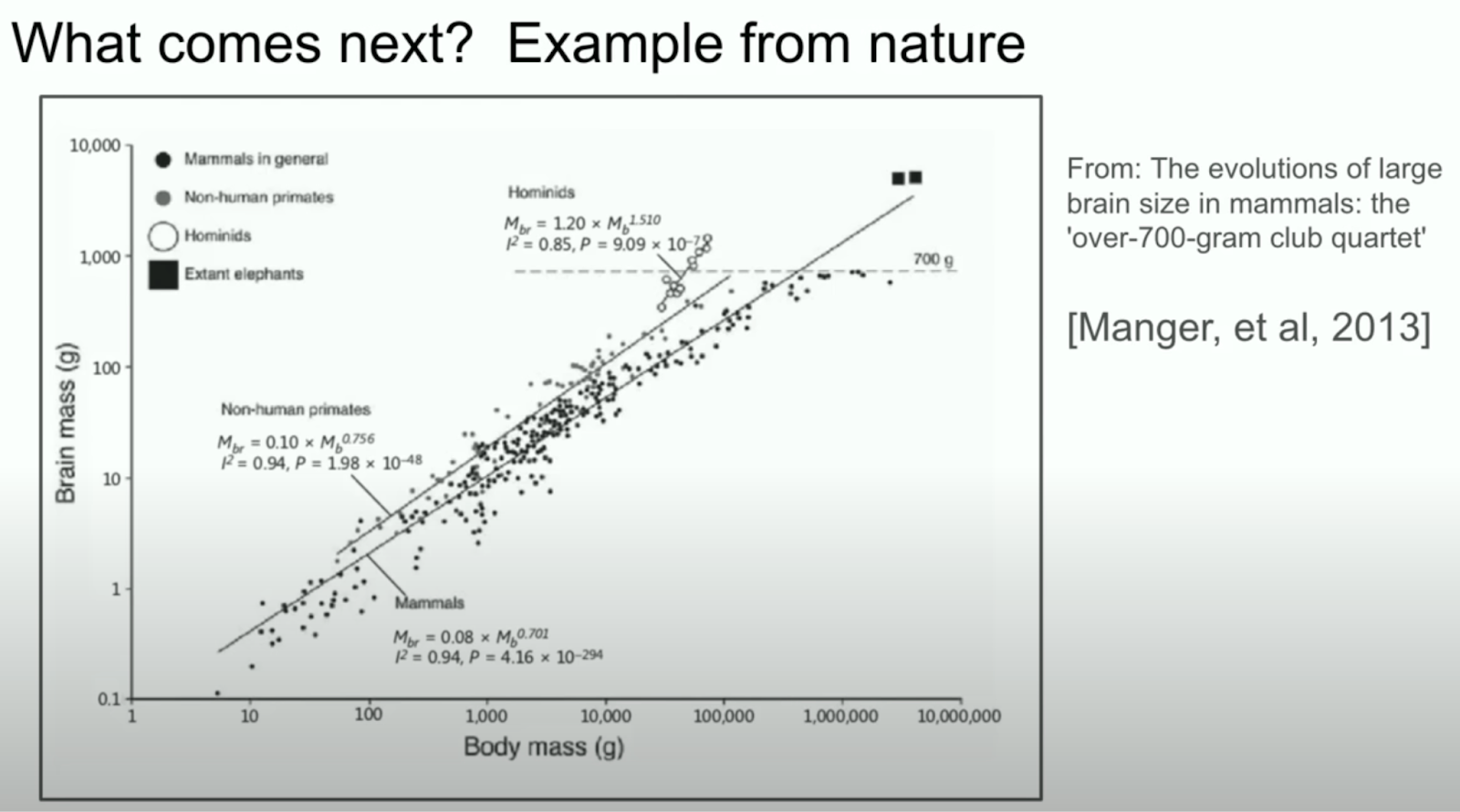
Example from nature
Scaling models via inference time compute
The cost of running LLMs today is spent on serving the inference (you send a prompt and get back a response) and the pre-training which is where you are getting the model ready for serving. While scaling models to very large size (1T+ parameters like the og GPT-4) works, it comes with a significant cost of having many many GPUs to run inference making it expensive.
On the other hand, various research has shown that just letting the model run inference for longer leads to dramatically better results. This was hinted at by the famous “Think step by step” and is now the very paradigm of improving performance of these models.
Various AI labs such as OpenAI, Google, Anthropic and Deepseek are training these models to think for longer by moving their compute budget from the training paradigm to inference time.
To quantify this, the training cost is going to be static while the inference cost can be dynamic based on the difficulty of the task.
This allows for better resource allocation as well since you can spend more resources on the harder tasks instead of the one time cost of pre-training.
In this new world you get the option to spend $10 on harder problems while the easy problems need just a dollar. This allows you to plan ahead given the complexity of the task and use more intelligence when required.
How many r’s in 🍓?
By putting more compute towards inference, these models get a super human-like ability in solving hard reasoning problems.
Humans are allowed an 'unfair' advantage to take however long to think on a problem, while 1st gen LLM's have to infer on a strict budget.
To allow LLM's the flexibility to use more compute/time on a problem levels the playing field, producing better results.
This allows these LLMs to have an almost PhD level intelligence when solving very hard maths and coding problems, generally domains which require 2-degree hops and more to come up with the right answer.
And finally almost all of these models are able to answer the r’s in 🍓! (almost!)
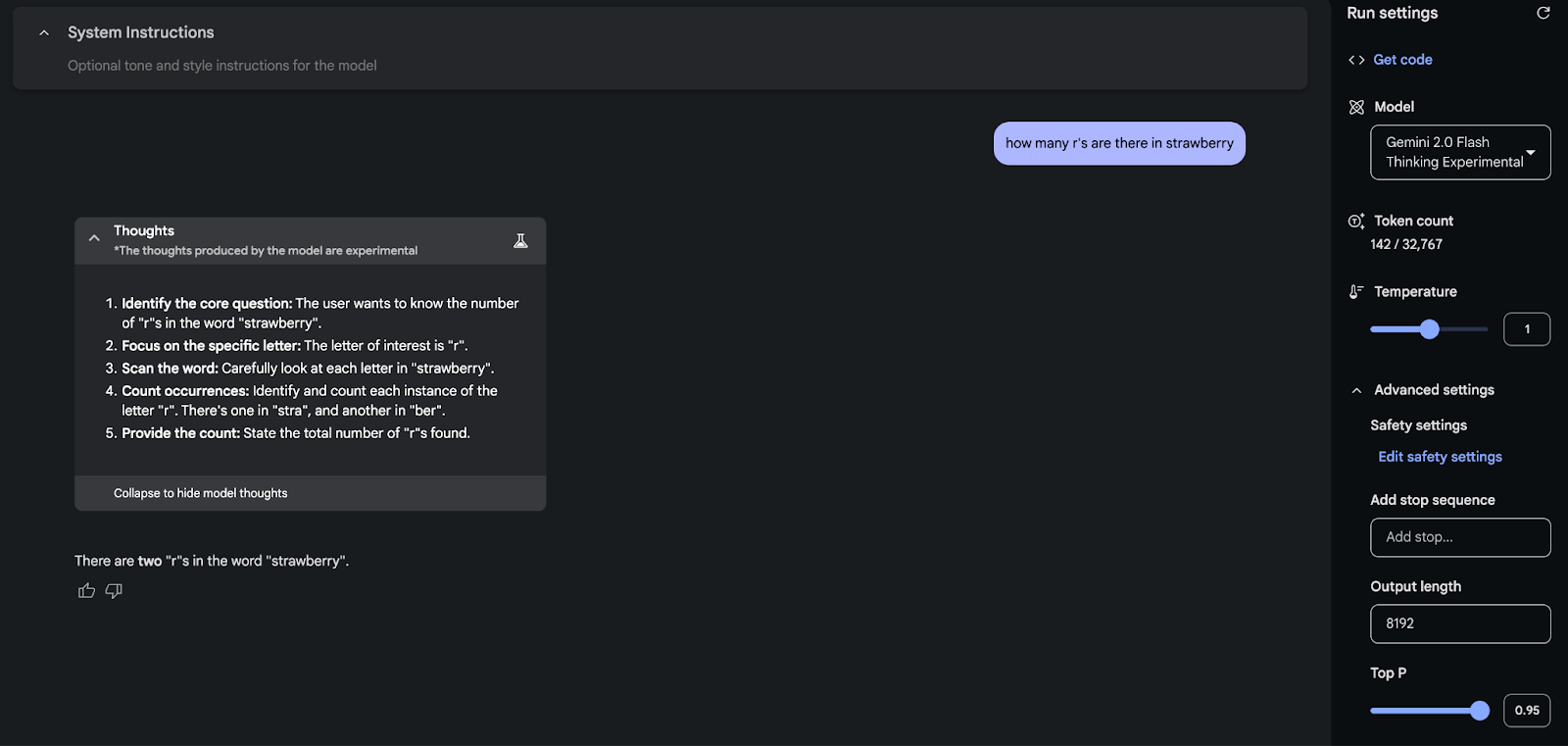
Flash Strawberries
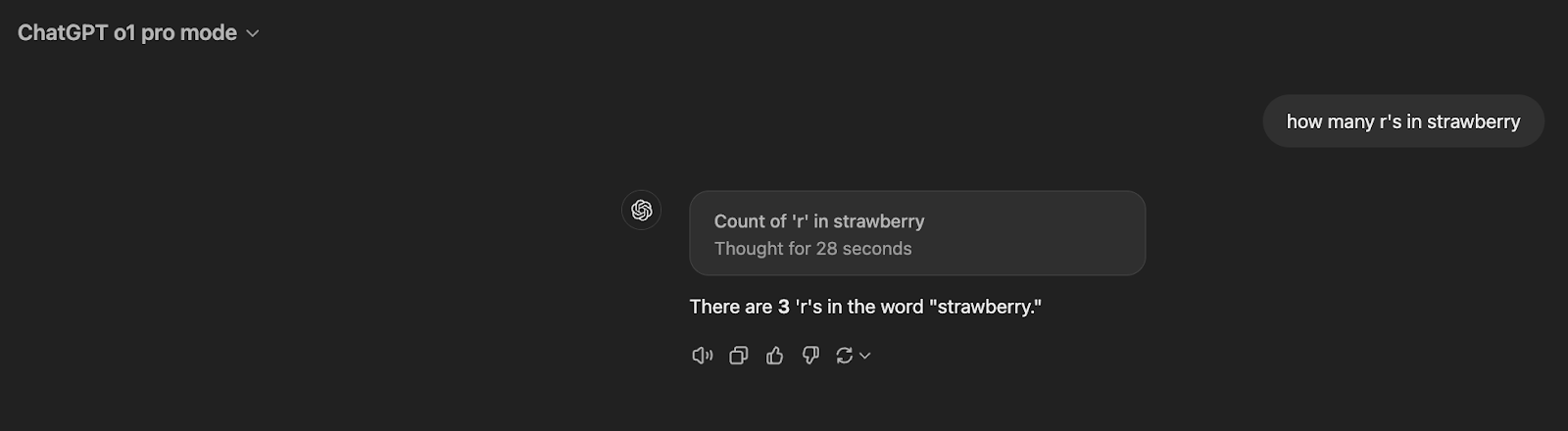
O1 Strawberry
Is this the final form of reasoning?
Oftentimes, the way humans go about solving hard problems is often expanding their search space incorporating new information in their thinking, tracing back.
These LLMs on the other hand today have access to just the initial context and can reason very deeply on that.
In the future maybe with a different architecture we will have models which actively go out of their way to use tools while running inference and incorporate new knowledge into their inference.
Allowing tool use today while actively running inference is not a scalable and sustainable solution since the GPUs are going to pause while waiting for the tool used to finish. This will not work at scale with any LLM provider and requires a different approach and maybe some engineering unlocks.
Using compute in parallel or sequentially?
While these thinking models are able to use compute and tokens sequentially, there is another powerful paradigm one whose roots are in the bitter lesson
> The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin
When we think about using compute, we can use models like o1-pro, r1, gemini-2.0-flash-thinking to use compute sequentially and to exhaustion.
The other angle is to parallelize the use of compute, i.e. throw 10 of these LLMs at the same problem.
Given LLMs are also non-deterministic, throwing more distinct LLMs at the problem often leads to better answers! This was the thesis of Alpha (Go|Chess|Code|Gemotry) and all these implementations are SOTA in their respective domains.
We are already seeing proof of test-time compute emerging as victorious in the realm of code-generation where we can push even sonnet3.5 to SOTA by genuinely brute-forcing and letting the model take as many steps as required and using as many agents as required
There will be new heights which we will achieve by brute-forcing and exhausting the search space. Given these LLMs are non-deterministic we should exploit this behavior to our advantage and double down on it.
The final question I would leave you with is: “Would you employ 1000s of interns or a demi-god?”